I am well aware that my game Democracy 4 is not exactly slow with huge framerate issues. However, optimization is fun! or at least it should be, but in practice, getting profiling to work on remote PCs is not exactly easy. I have basically used every profiling software imaginable and still have not got one that I think really does the job well…
I have basically wasted about an hour today trying to work out why I couldn’t get the intel vtune amplifier stuff to work with event based profiling and get rid of this pesky error that was clearly nonsense about ‘not able to recognize processor… until I finally realized that I actually have an AMD chip in my (relatively) new PC so…yeah… That drove me to try out the AMD uProf profiler, which is something I had not used before.
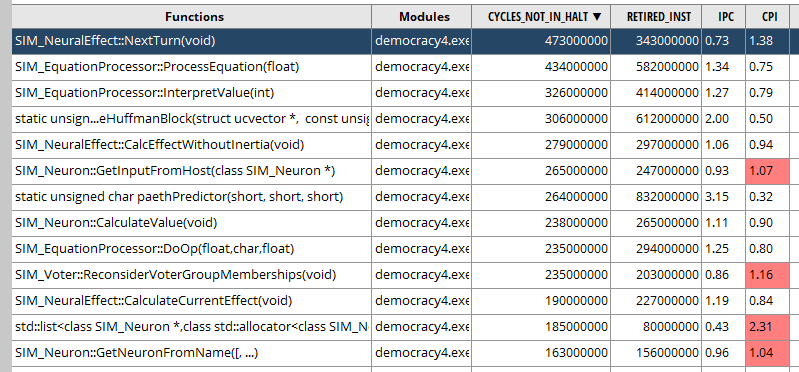
It took me a moment to realize that this software, good though it is, does not suggest to you ‘hey if you run me in administrator mode I will show you 50x more config options’ but luckily I worked that out. My first act was a brief run of Democracy 4, starting a new game then immediately going to the next turn. In the list of functions taking up all the time (and ignoring windows system functions) I get this list:
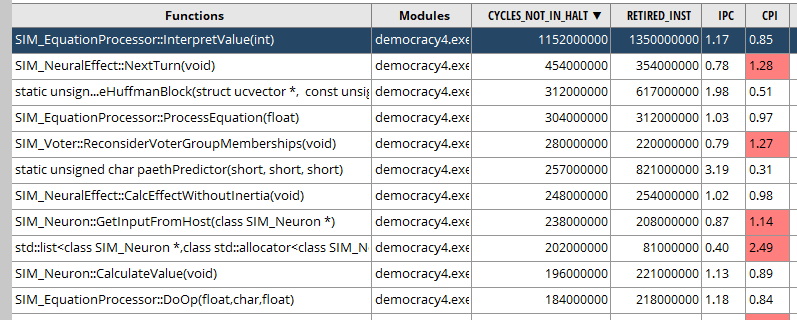
Which is about what I would expect. The game is implemented as custom-coded neural network structure, hence the terminology. Mostly everything is a neuron, and most of the processing is where each neural effect (the links between neurons) processes its equation, and then neurons do some math on their inputs and outputs.
The inner machinery of the neural network ultimately comes down to that top item there:
SIM_EquationProcessor::Interpret Value.
This is code that basically takes those equations in the game’s csv files like this:
StateHealthService,0-(0.4*x),2
And actually calculates a value from that. There are 2,000 voters with about 10 connections each, pre-processed on a new game 32 times, so thats 640,000 equations right there, plus all of the actual simulation stuff layered before that. In other words, that equation processer probably runs a million times on a new game, and the equation might have 5 values in it, so max case is 5 million values get interpreted when you click on ‘new game’.
Can I speed it up?
First step is to see how stable these values are any way, so I’ll do an identical profile run and check that the +/- errors on different profiling runs are small…
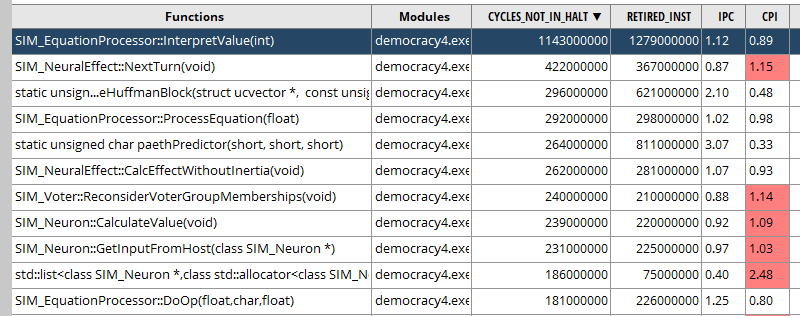
I think thats pretty close. I definitely have numbers here that are in the same ballpark. So now lets try some optimisations to speed this puppy up. Looking at the top function with a double-click gives me a whole bunch more data:
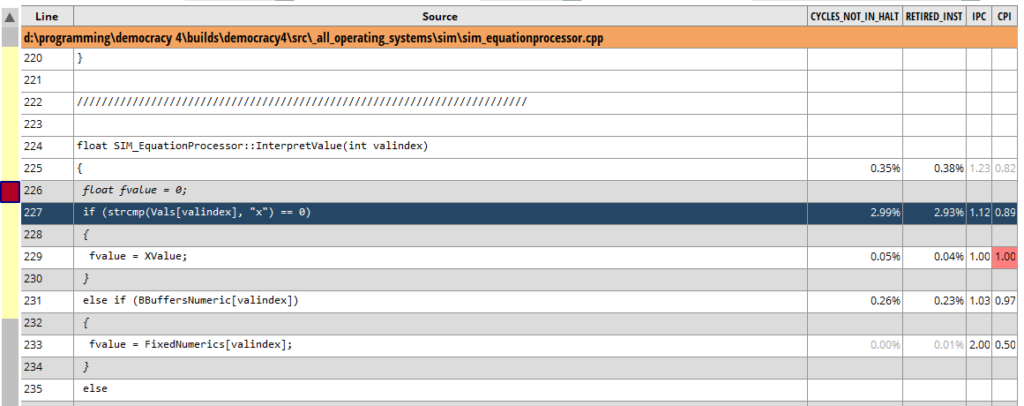
The function is much longer than this, but thats mostly catering to relatively rare edge cases. Looking at the bits that actually have numbers on it show pretty clearly that its pretty much all about the pesky strcmp() call. A separate piece of code has already parsed the full equation of 0-(0.4*x), so I have a bunch of char buffers for each variable, declared like this:
char Vals[MAX_VARIABLES][32];
The thing is, do I need the overhead of calling strcmp() when I am only really checking for whether the first letter is x? Sadly I cannot JUST check that, because that would prevent we having a named variable starting with an x. Lets imagine this equation:
0-(0.4*xylophone)
Obviously not very likely, but theoretically possible. If the length of the buffer was 1, and the first letter is x, then thats a hit, but the question is, will inlining 2 manual checks be faster than a strcmp function call? Lets replace that code with
if(Vals[valindex][0] == 'x' && Vals[valindex][1] == '\0')
And check out the results:
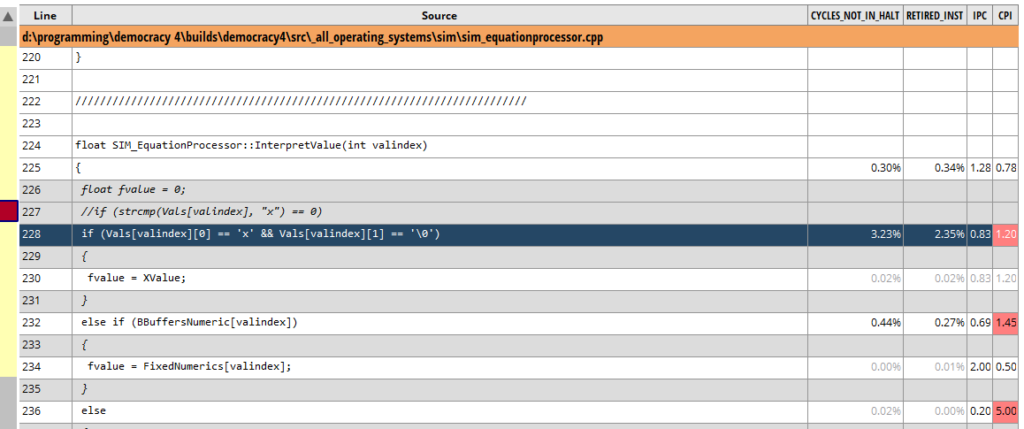
Hmmm. Actually WORSE as far as I can tell. So it looks like whether we strcmp or not, just checking the value of two bytes at that point is slow. probably because its not immediately available memory? Its notable that the code at line 232 is super fast by comparison, as its just checking a bool value we cached earlier. Maybe I should try that? When I parse the function, just keep a bool for each Value, saying if its ‘x’ or not?
Whoahh. This looks like a pretty major speedup. 326 cycles versus 1,143. What the hell? why didn’t I do this earlier? Lets look at the line by line…
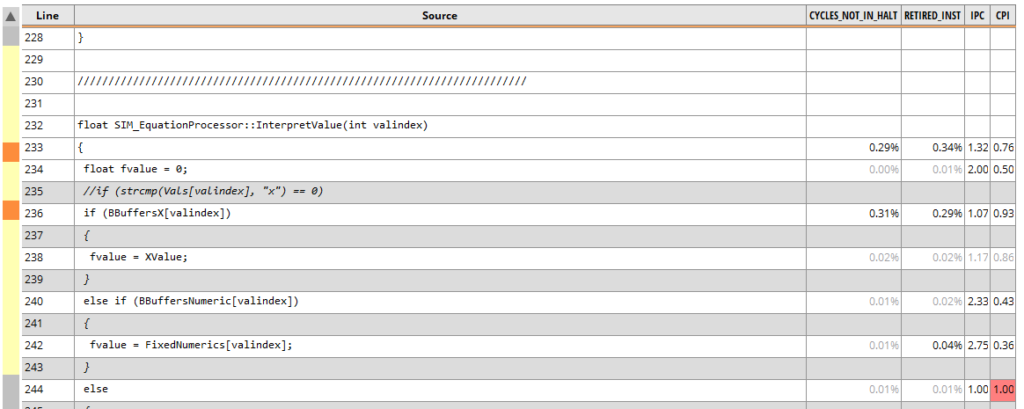
This is awesome. I then tried to make this code inline, but it seemed to not make things any better. I haven’t fully explored uProf yet, but it does do cool flame graphs:
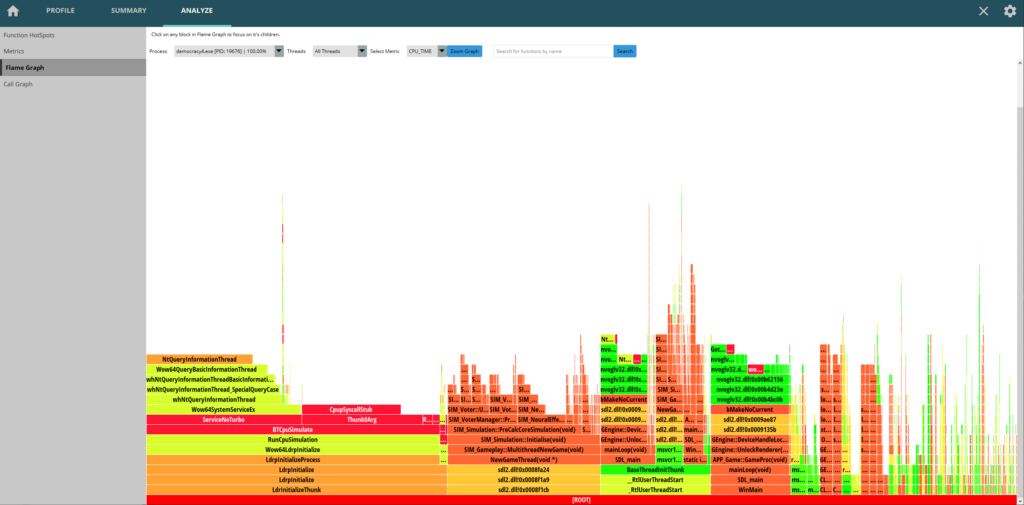
Profiling UIs are great fun :D